
参考文献
-
《Edge Computing: Vision and Challenges》
- IEEE INTERNET OF THINGS JOURNAL, VOL. 3, NO. 5, OCTOBER 2016
-
边缘云计算技术及标准化白皮书(2018) - 中国电子技术标准化研究
- 阿里云计算有限公司 中国电子技术标准化研究院 等 2018 年 12 月 12 日联合发布
-
**《基于个人计算机的智能家居边缘计算系统》**计算机学报,上海交通大学 计算机科学与工程系
一、引言
1. IT 3.0 时代会发生什么?
- 很久之前,电力 1.0 时代,想要用电,需要自己买发电机
- 不久之前,电力 2.0 时代,有了电网,想要用电,直接从电网购买即可,用多少买多少
- 当今,电力 3.0 时代,在很多发达国家,不少用户家里安装了太阳能板,有些可以电力自给自足,有些甚至有富裕,可以把电反哺电网,赚取收入
如果你混迹于 IT 圈子,你会发现类似的现象:
- 不久之前,IT 1.0 时代,每个公司想要处理数据,要自备机房,自己买服务器
- 现如今,IT 2.0 时代,有了云计算,公司直接购买云服务器和云计算力即可,用多少买多少
- 即将到来的 IT 3.0 时代,你觉得会发生什么?
闲散的计算力收集和再利用,形成雾计算!
云计算是可配置计算机资源和更高级别服务的共享池,可以通过最少的管理工作快速配置(一般是用互联网);
其实,云计算你可以理解为资源共享池。举个例子就是,我有很多东西,家里放不下了,放到一个特定的地方存着,随时提取,别人碰不了,保质保量。

华为《GIV2025 打开智能世界产业版图》白皮书
2. Cloud, Fog and Edge Computing – What’s the Difference?
实践场景

智慧城市
如果将智能家居的应用场景放大到一个社区或城市,将在公共安全、健康数据、公共设施、交通运输等众多细分领域产生极大的应用价值。这里应用边缘计算的初衷更多是出于成本和效率考虑,在一个八百万人口规模的城市,每小时产生的数据量可能达到 100PB,采用传统云计算处理方式将给网络带宽带来极大的压力,城市各角落的边缘设备实时处理和收集数据将带来效率上的极大提升。
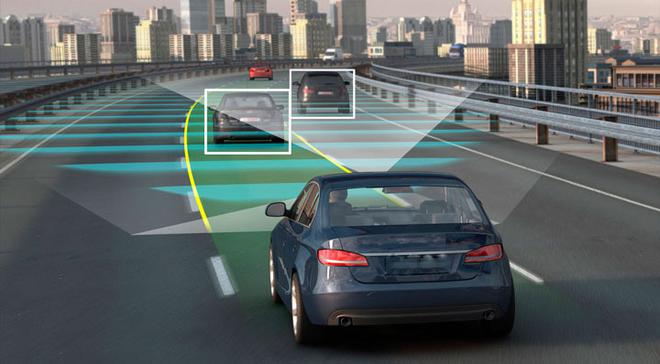
自动驾驶技术与智能交通
在自动驾驶领域,边缘计算至关重要,因为**自动驾驶汽车上数百个传感器每小时将产生 40TB 的数据量。**从安全性的角度而不是从成本的角度考虑,数据的处理必须实时完成,当遇到紧急情况时,比如汽车前方突然出现踢球玩耍的小孩,这时自动驾驶系统必须依赖实时高效的边缘计算给予决策支持,并作出应急处理:刹车!
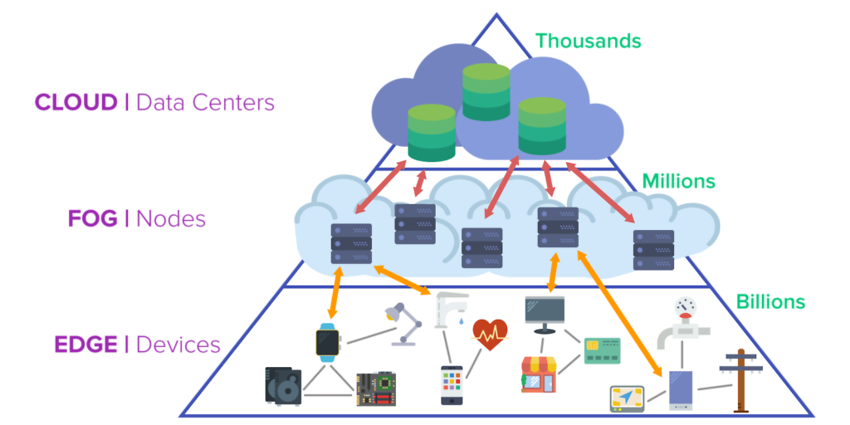
云计算(Cloud Computing)
云计算(英语:cloud computing),是一种基于互联网的计算方式,通过这种方式,共享的软硬件资源和信息可以按需求提供给计算机各种终端和其他设备。
边缘计算(Edge Computing)
Edge computing—also known as just “edge”—brings processing close to the data source, and it does not need to be sent to a remote cloud or other centralized systems for processing. By eliminating the distance and time it takes to send data to centralized sources, we can improve the speed and performance of data transport, as well as devices and applications on the edge.
在科技飞速发展的今天,物联网已经成为公共云上运行的关键工作负载之一。**虽然现在云端物联网价值很大,但数据延迟和宽带消耗时它面临的最大问题。**毕竟现在这个时代,时间既金钱。为了解决这个问题,边缘计算应运而生。当有了边缘设备来充当“端”和“云”之间的中介,即可通过云的物联网来控制平面,从而进行更加集中化的管理。
举一个不太恰当,但能帮助理解的例子。把云端比作班主任,班主任很厉害吧。但一个班四五十个人,如果事无巨细的由班主任来决定,浪费时间还效率不高。这时各个班委出现了。选择一些有独立处理班级事务能力的同学,来分摊全班的事务。效率提升了不说,也减轻了班主任的负担。边缘计算就好比这些班委。帮云计算分担那些边缘的问题,从而起到省时省力的作用。
用人体神经举个例子,云计算就是身体所有反应都需要经过大脑处理后作出。而边缘计算就是由神经条件反射。
雾计算(Fog Computing)
Fog computing is a standard that defines how edge computing should work, and it facilitates the operation of compute, storage and networking services between end devices and cloud computing data centers. Additionally, many use fog as a jumping-off point for edge computing.
Fog computing, a term created by Cisco, also refers to extending computing to the edge of the network. Cisco introduced its fog computing in January 2014 as a way to bring cloud computing capabilities to the edge of the network.
3. 云计算是如何服务的
说到这里不得不说一下云计算的服务和交付方式,就是大家常见的 IaaS、PaaS、SaaS。
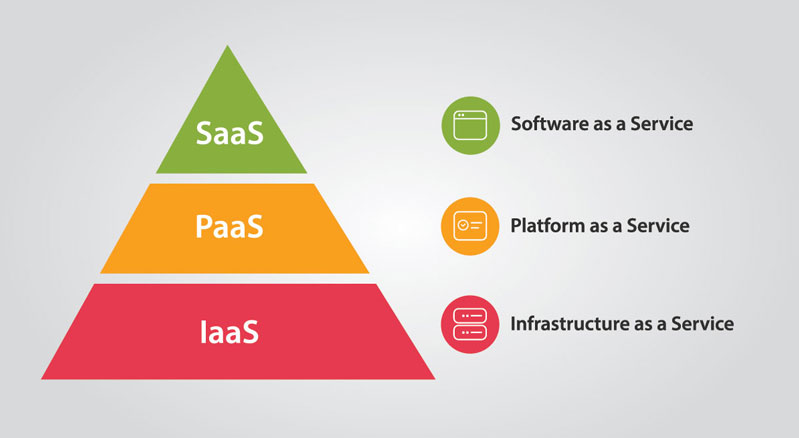
What is IaaS
IaaS 其实是 “Infrastructure as a service” 的英文缩写,翻译过来是 “基础设施作即服务”,为了方便使用就成为了 “IaaS”。
IaaS 就是用户通过购买/租用云虚拟服务器来使用云服务的交付方式,现阶段的企业用户使用较少。
What is PaaS
PaaS “Platform as a Service” 平台即服务。云计算公司把应用服务的运行和开发环境作为服务提供给用户,用户可以在这个平台上开发自己的云。国内像阿里、华为、腾讯、金山云等公司都会提供这样的服务。
What is SaaS
SaaS“Soft as a Service” 软件即服务,云服务开发商通常将软件定位在云上,用户通过购买软件来使用云的一种交互方式。我们经常用到的钉钉、WPS 云办公等企业软件就是 SaaS 的一种表现形式。
4. 私有云、公有云、混合云
私有云
私有云从字面意思上了解就是私有的云,用户自己开发或者是云计算公司为用户单独使用而开发的云就是私有云。私有云的开发成本很高,需具备一定的硬件和软件基础,但是安全性方面是三云中最高的。
共有云
公有云一般指大家都能用的云,一般来说会收取用户相对较少的费用或者免费使用。我们日常生活中,最常用的百度云盘、微信云等都是公有云,当然三大通讯运营商所使用的云也是公有云。方便是公有云最大的特点,安全性是公有云的不足。
混合云
混合云融合公有云和私有云,是未来云计算市场的发展趋势。企业客户既希望于将数据放在私有云上保持独立性和安全性,又希望借助公有云的平台实现资源的共享。混合云匹配私有云和公有云,既保证了安全也达到了节省成本,提高效率的目的,目前已经应用在医疗领域。
二、再谈边缘计算
1. 引言
在聊边缘计算之前,我们先聊聊这个星球上最魔性的生物之一——章鱼。

具体来讲,边缘计算将数据的处理、应用程序的运行甚至一些功能服务的实现,由网络中心下放到网络边缘的节点上。
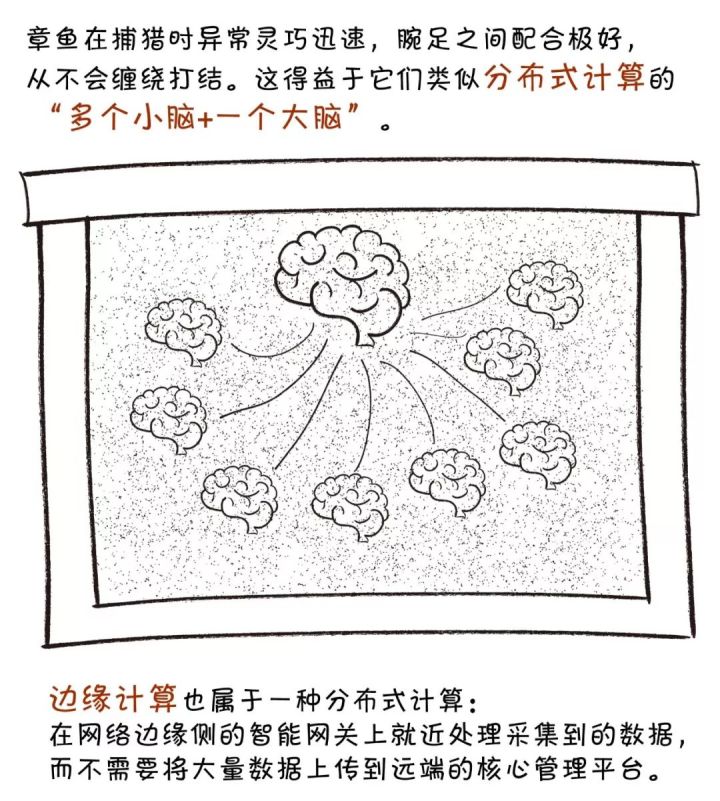
一直以来,公共和企业设施的监测和维护消耗着大量的人力、物力成本;电力、制造等行业数字化转型中对海量数据的实时、智能处理也有着强烈需求。
如果用常规模式构建物联网,随着设备的迅速增加,网络边缘侧所产生的数据量级将非常巨大。这些数据如果都交由云端的管理平台来处理,将会:
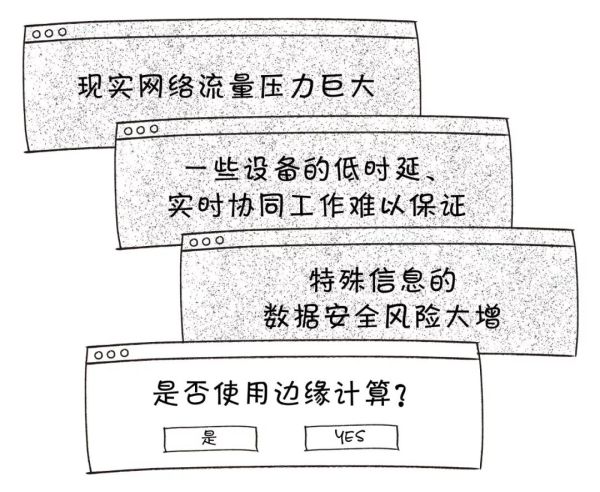
2. 什么是边缘计算
在网络边缘产生的数据正在逐步增加,如果我们能够在网络的边缘结点去处理、分析数据,那么这种计算模型会更高效。许多新的计算模型正在不断的提出,因为我们发现随着物联网的发展,云计算并不总是那么高效的。接下来文章中将会列出一些原因来证明为什么边缘计算能够比云计算更高效,更优秀。
3. 为什么需要边缘计算
云服务的推动:云中心具有强大的处理性能,能够处理海量的数据。但是,将海量的数据传送到云中心成了一个难题。云计算模型的系统性能瓶颈在于网络带宽的有限性,传送海量数据需要一定的时间,云中心处理数据也需要一定的时间,这就会加大请求响应时间,用户体验极差。
物联网的推动:现在几乎所有的电子设备都可以连接到互联网,这些电子设备会后产生海量的数据。传统的云计算模型并不能及时有效的处理这些数据,在边缘结点处理这些数据将会带来极小的响应时间、减轻网络负载、保证用户数据的私密性。
终端设备的角色转变:终端设备大部分时间都在扮演数据消费者的角色,比如使用智能手机观看爱奇艺、刷抖音等。然而,现在智能手机让终端设备也有了生产数据的能力,比如在淘宝购买东西,在百度里搜索内容这些都是终端节点产生的数据。
图 1 是传统云计算模型下,最左侧是服务提供者来提供数据,上传到云中心,终端客户发送请求到云中心,云中心响应相关请求并发送数据给终端客户。终端客户始终是消费者的角色。
图
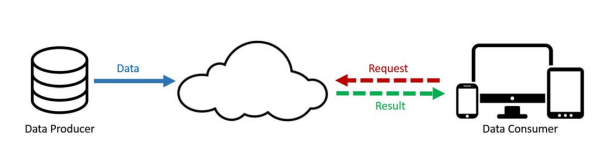
图1 云计算模型
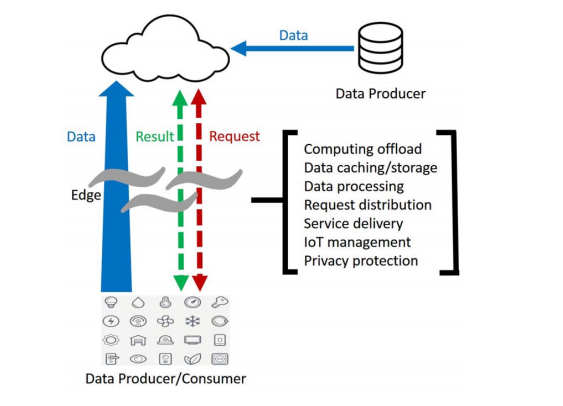
图2 边缘计算模型
4. 边缘计算的优点
- 在人脸识别领域,响应时间由 900ms 减少为 169ms
- 把部分计算任务从云端卸载到边缘之后,整个系统对能源的消耗减少了 30%-40%。
- 数据在整合、迁移等方面可以减少 20 倍的时间。
TensorFlow.js | TensorFlow
https://www.tensorflow.org/js/demos
三、边缘智能:基于边缘计算的深度学习模型推断加速方法
生态
产业三分天下,拥有终端、算法、算力者通吃
目前,边缘智能产业生态架构已形成,主要有三类玩家:
第一类:算法玩家。从算法切入,如提供计算机视觉算法、NLP算法等。
第二类:终端玩家。从硬件切入,如提供手机、PC等智能硬件。
第三类:算力玩家。从终端芯片切入,如开发用于边缘计算的AI芯片等。
研究背景
作为人工智能领域的当红炸子鸡,深度学习技术近年来得到了学术界与产业界的大力追捧。目前,深度学习技术已在计算机视觉、自然语言处理以及语音识别等领域大放异彩,相关产品正如雨后春笋般涌现。**由于深度学习模型需要进行大量的计算,因此基于深度学习的智能通常只存在于具有强大计算能力的云计算数据中心。**考虑到当下移动终端设备的高度普及,如何将深度学习模型高效地部署在资源受限的终端设备,从而使得智能更加贴近用户这一问题以及引起了学术界与工业界的高度关注。针对这一难题,边缘智能(Edge Intelligence)技术通过协同终端设备与边缘服务器,来整合二者的计算本地性与强计算能力的互补性优势,从而达到显著降低深度学习模型推理的延迟与能耗的目的。
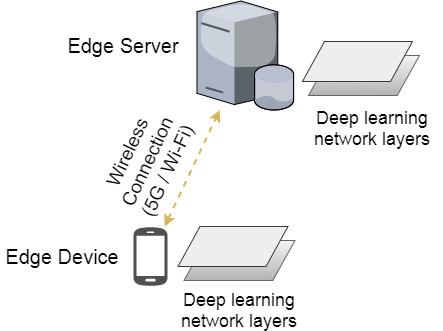
图1. 基于终端设备与边缘服务器协同的深度学习推断
边缘智能的核心研究问题在于如何在资源受限的边缘端高效部署深度学习模型,其中包括边缘设备深度学习模型优化,深度学习计算迁移,边缘服务器与终端设备间的协同调度等问题。
研究问题
对于常见的常见的深度学习模型,如深度卷积神经网络 CNN,是由多层神经网络相互叠加而成。由于不同网络层的计算资源需求以及输出数据量都具有显著的差异性,那么一个直观的想法是将整个深度学习模型切分成两部分,其中计算量大的一部分卸载到边缘端服务器进行计算,而计算量小的一部分则保留在终端设备本地计算,如图 2 所示。显然,上述终端设备与边缘服务器协同推断的方法能有效降低深度学习模型的推断时延。然而,选择不同的模型切分点降导致不同的计算时间,我们需要选择最佳的模型切分点从而最大化发挥终端与边缘协同的优势。
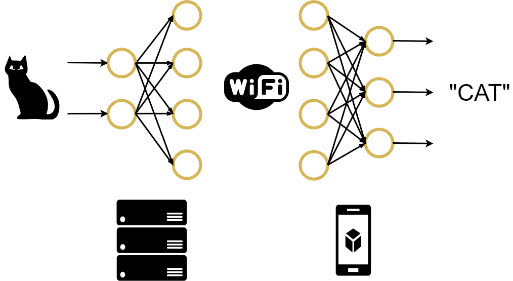
图2. 边缘服务器与终端设备协同推理示例
除了对模型进行切分(DNN partitioning),加速深度学习模型推断的另一手段为**模型精简(DNN right-sizing),即选择完成时间更快的“小模型”,而非对资源需求更高的“大模型”。**如图 3 所示,对于任意深度学习任务,我们可以离线训练具有多个退出点的分支网络,其中,退出点越靠后,模型越“大”, 准确率也越高但相应地推断时延越大。因此,当深度学习任务的完成时间比较紧迫时,我们可以选择适当地牺牲模型的精确度来换取更优的性能(即时延)。值得注意的是,此时我们需要谨慎权衡性能与精度之间的折衷关系(tradeoff)。
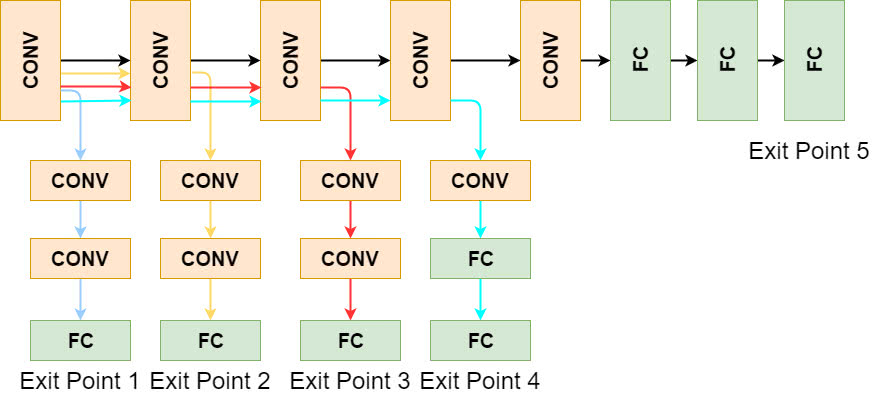
图3. 具有多个退出点的深度学习分支网络
综合运用上述模型切分和模型精简等两种调节深度学习模型推断时间的优化手段,并小心权衡由此引发的性能与精度之间的折衷关系,本文定义如下研究问题:对于给定时延需求的深度学习任务,如何联合优化模型切分和模型精简这两个决策,从而使得在不违反时延需求的同时最大化深度学习模型的精确度。
研究结果
针对上述问题,我们提出了基于边缘与终端协同的深度学习模型运行时优化框架Edgent。如图4所示,Edgent 的优化逻辑分为三个阶段:离线训练阶段,在线优化阶段以及协同推断阶段。
首先,在离线训练阶段,Edgent训练深度学习任务对应的分支网络,并生成回归模型来预测分支网络中不同网络层在边缘服务器以及在终端设备上的计算时间。其次,在在线优化阶段,Edgent实时测量当前移动终端与边缘服务器之间链路的网络带宽,以便于估算移动终端与边缘服务器间的数据传输时延。紧接着,Edgent沿着尺寸从大到小的网络分支(如图3中从右至左的5个网络分支),依次遍历每个网络分支上不同的切分点,并基于当前网络带宽和不同网络层计算时间估算所选网络分支与切分点对应的端到端延迟与模型精确度。在遍历完所有的分支网络与切分点后,Edgent输出满足时延需求的所有网络分支与切分点组合中具有最大精确度的一个组合。最后,在协同推断阶段,根据上述在线优化阶段所输出的最优网络分支与切分点组合,边缘服务器与移动终端对深度学习模型进行协同推断。
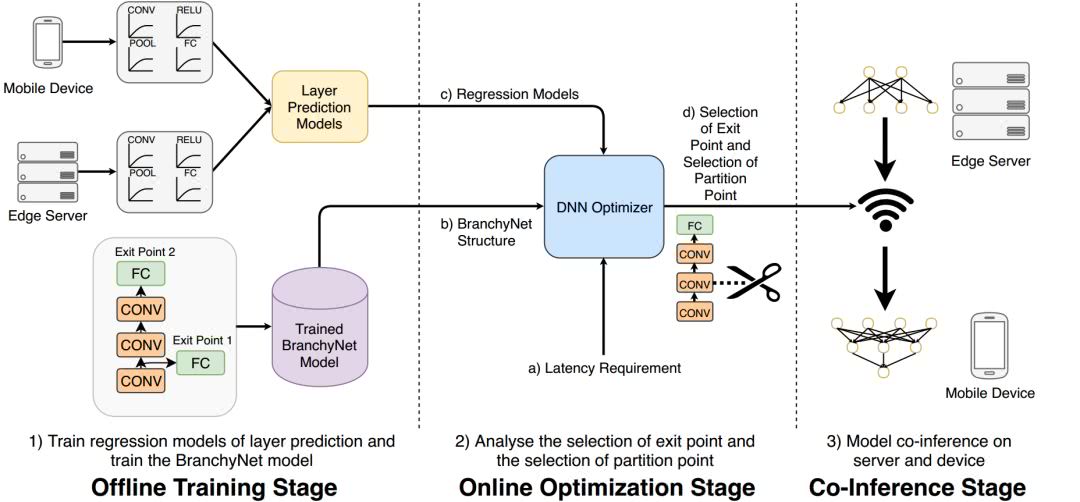
图4. 基于边缘与终端协同的深度学习模型运行时优化框架 Edgent

